Build a fast MEV bot with Alloy's Primitive Types
Alloy is a successor to the deprecated ethers-rs. In this guide, we will describe how you can reap the benefits of its better performance with minimal codebase changes to ethers-rs project. We will also implement an atomic UniswapV2 arbitrage simulation to showcase how different parts of the Alloy stack fit together.
Read on to learn how the benchmark in the examples repository measures Alloy's U256 at up to
2× faster than ethers-rs for this workload.
How to calculate optimal UniV2 arbitrage profit?
An atomic arbitrage between two UniswapV2 pairs is one of the more basic MEV techniques. We will use this example to discuss the performance characteristics of ethers-rs vs Alloy.
To execute an atomic arbitrage swap, you have to calculate the required input and output token amounts. UniswapV2 calculations can be done off-chain (i.e., without interacting with deployed Smart Contracts) with a relatively simple equation.
Most publicly available bots use an iterative search function to find an optimal amount of input value. However, UniswapV2 constant product formula makes it possible to calculate a profitable input amount without multiple iterations. We will borrow the implementation of this formula from Flashbots simple-blind-arbitrage repo. You can find a step-by-step explanation of how to derive the formula in this YouTube video.
All the code examples for this post are available in the
advanced examples, with
shared implementations in the helpers crate.
Let's start with implementing a struct representing a Uniswap pool and a few helper functions in Alloy:
use alloy::primitives::{address, Address, U256};
pub static WETH_ADDR: Address = address!("C02aaA39b223FE8D0A0e5C4F27eAD9083C756Cc2");
#[derive(Debug)]
pub struct UniV2Pair {
pub address: Address,
pub token0: Address,
pub token1: Address,
pub reserve0: U256,
pub reserve1: U256,
}
// https://etherscan.io/address/0xA478c2975Ab1Ea89e8196811F51A7B7Ade33eB11
pub fn get_uniswap_pair() -> UniV2Pair {
UniV2Pair {
address: address!("A478c2975Ab1Ea89e8196811F51A7B7Ade33eB11"),
token0: DAI_ADDR,
token1: WETH_ADDR,
reserve0: uint!(6227630995751221000110015_U256),
reserve1: uint!(2634810784674972449382_U256),
}
}
pub fn get_amount_out(reserve_in: U256, reserve_out: U256, amount_in: U256) -> U256 {
let amount_in_with_fee = amount_in * U256::from(997_u64); // uniswap fee 0.3%
let numerator = amount_in_with_fee * reserve_out;
let denominator = reserve_in * U256::from(1000_u64) + amount_in_with_fee;
numerator / denominator
}
pub fn get_amount_in(
reserves00: U256,
reserves01: U256,
is_weth0: bool,
reserves10: U256,
reserves11: U256,
) -> U256 {
let numerator = get_numerator(reserves00, reserves01, is_weth0, reserves10, reserves11);
let denominator = get_denominator(reserves00, reserves01, is_weth0, reserves10, reserves11);
numerator * U256::from(1000) / denominator
}
//...Implemenation details are omitted for brevity.
UniV2Pair struct represents pools that we will be working with. get_amount_out is a standard calculation for determining how much of a given ERC20 you can buy from the pool after paying the protocol fees. get_amount_in is the profitable input amount formula that we borrow from Flashbots repo.
It's worth noting that we use handy address! and uint! macros to generate the compile time constant Address and U256 types.
Iterative UniswapV2 profit algorithm
Let's consider the following example: your MEV bot wants to score an arbitrage between UniswapV2 and Sushiswap WETH/DAI pools. Here's how you can calculate the arbitrage in a standard way:
- calculate how much DAI you can buy from the UniswapV2 pool for a sample WETH input amount
- calculate how much WETH you can buy back from Sushi pool for the previously calculated DAI amount
- repeat the process for multiple values to determine which yields the best profit
The above algorithm is iterative. There are ways to minimize the number of iterations, but this topic is outside the scope of this tutorial.
Arbitrage profit formula
Instead, we can use the get_amount_in method, which does more number crunching than get_amount_out but produces a profitable input amount in a single iteration Let's see it in action.
In the following example, we use a mocked pool reserve value for UniswapV2 and SushiSwap WETH/DAI Mainnet pools to simulate a profitable arbitrage opportunity.
fn main() -> Result<()> {
let uniswap_pair = get_uniswap_pair();
let sushi_pair = get_sushi_pair();
let amount_in = get_amount_in(
uniswap_pair.reserve0,
uniswap_pair.reserve1,
false,
sushi_pair.reserve0,
sushi_pair.reserve1,
);
let dai_amount_out = get_amount_out(uniswap_pair.reserve1, uniswap_pair.reserve0, amount_in);
let weth_amount_out = get_amount_out(sushi_pair.reserve0, sushi_pair.reserve1, dai_amount_out);
if weth_amount_out < amount_in {
println!("No profit detected");
return Ok(());
}
let profit = weth_amount_out - amount_in;
println!("Alloy U256");
println!("WETH amount in {}", display_token(amount_in));
println!("WETH profit: {}", display_token(profit));
Ok(())
}You can run it like that:
cargo run --locked -p examples-advanced --example uniswap_u256_alloy_profit
It should produce:
Alloy U256
WETH amount in 2.166958497387277956
WETH profit: 0.006142751241793559
We've calculated a profitable Arbitrage for our mocked Uniswap pool reserves!
"ethers-rs good, Alloy better!"
If you compare the implementations in helpers/src/alloy.rs
and helpers/src/ethers.rs,
you will notice that they are almost identical. Rewriting your project calculations from ethers-rs
to Alloy U256 should be possible with a very reasonable development effort. But is it worth it?
It's high time to compare the performance of legacy ethers-rs U256 with the brand-new (based on the ruint crate) Alloy integer type. We will use the criterion.rs crate. It generates reliable benchmarks by executing millions of iterations and turning off some compiler optimizations.
You can find the source of the benchmark in benches/u256.rs and execute it by running cargo bench U256
We compare the performance of both get_amount_in and get_amount_out. Benchmark indicates ~1.5x-2x improvement when using Alloy types!
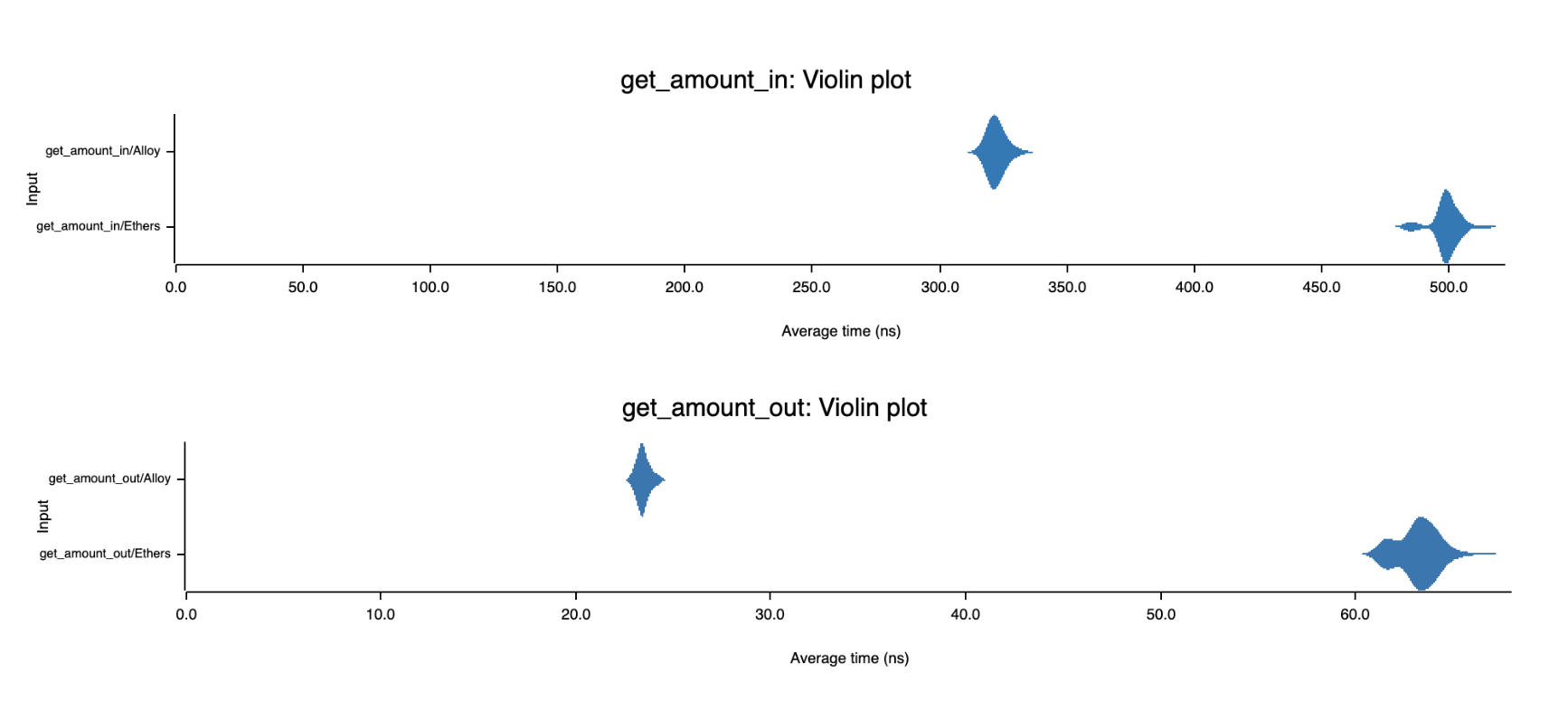
On the above charts generated with criterion.rs you can see that Alloy is consistently faster for both methods and has less variation in execution time.
This means that you can significantly improve the performance of your ethers-rs project by switching to the new U256 type.
Here's how you can convert between the two types:
use alloy::primitives::U256;
use ethers::types::U256 as EthersU256;
pub trait ToEthers {
type To;
fn to_ethers(self) -> Self::To;
}
impl ToEthers for U256 {
type To = EthersU256;
#[inline(always)]
fn to_ethers(self) -> Self::To {
EthersU256(self.into_limbs())
}
}use ethers::types::U256;
use alloy::primitives::U256 as AlloyU256;
pub trait ToAlloy {
type To;
fn to_alloy(self) -> Self::To;
}
impl ToAlloy for U256 {
type To = AlloyU256;
#[inline(always)]
fn to_alloy(self) -> Self::To {
AlloyU256::from_limbs(self.0)
}
}This trait can easily be applied to any ethers-rs and Alloy types. You can check out these conversion docs for details on how to do it.
How to simulate MEV arbitrage with Alloy?
Let's confirm that our calculations are correct by simulating the arbitrage swap. We will use a new Alloy stack to fork Anvil and mock the profit opportunity.
Mocking the forked blockchain storage slots is an insanely useful technique. It allows to recreate any past blockchain state without an archive node. Geth full node by default prunes any state older than the last 128 blocks, i.e., only ~25 minutes. Using a forked blockchain saves a lot of effort in seeding the contract bytecodes. You can cherry-pick the exact EVM storage slots and modify them to match your desired simulation state. Anvil will implicitly fetch all the non-modified state from its origin blockchain.
Here are the helper methods that we'll use:
pub async fn set_hash_storage_slot<P: Provider>(
anvil_provider: P,
address: Address,
hash_slot: U256,
hash_key: Address,
value: U256,
) -> Result<()> {
let hashed_slot = keccak256((hash_key, hash_slot).abi_encode());
anvil_provider.anvil_set_storage_at(address, hashed_slot.into(), value.into()).await?;
Ok(())
}We will leverage a custom Anvil RPC method, anvil_setStorageAt, to mock EVM storage values. set_hash_storage_slot method is used to overwrite values inside mappings. It implements a Solidity convention where the storage slot of a mapping value is keccak256 of the storage slot of the mapping and the key.
And here's our simulation:
uniswap_u256_alloy_simulation.rs
// imports omitted for brevity
sol! {
function swap(uint amount0Out, uint amount1Out, address to, bytes calldata data) external;
}
sol!(
#[sol(rpc)]
contract IERC20 {
function balanceOf(address target) returns (uint256);
}
);
sol!(
#[sol(rpc)]
FlashBotsMultiCall,
"examples/abi/FlashBotsMultiCall.json"
);
#[tokio::main]
async fn main() -> Result<()> {
let uniswap_pair = get_uniswap_pair();
let sushi_pair = get_sushi_pair();
let wallet_address = address!("0xf39Fd6e51aad88F6F4ce6aB8827279cffFb92266");
let rpc_url = rpc_url()?;
let provider =
ProviderBuilder::new().connect_anvil_with_wallet_and_config(|anvil| anvil.fork(rpc_url))?;
let executor = FlashBotsMultiCall::deploy(provider.clone(), wallet_address).await?;
let iweth = IERC20::new(WETH_ADDR, provider.clone());
// Mock WETH balance for executor contract
set_hash_storage_slot(
provider.clone(),
WETH_ADDR,
U256::from(3),
*executor.address(),
parse_units("5.0", "ether")?.into(),
)
.await?;
// Mock reserves for Uniswap pair
provider
.anvil_set_storage_at(
uniswap_pair.address,
U256::from(8), // getReserves slot
B256::from_slice(&hex!(
"665c6fcf00000000008ed55850d607f83a660000000526c08d812099d2577fbf"
)),
)
.await?;
// Mock WETH balance for Uniswap pair
set_hash_storage_slot(
&provider,
WETH_ADDR,
U256::from(3),
uniswap_pair.address,
uniswap_pair.reserve1,
)
.await?;
// Mock DAI balance for Uniswap pair
set_hash_storage_slot(
&provider,
DAI_ADDR,
U256::from(2),
uniswap_pair.address,
uniswap_pair.reserve0,
)
.await?;
// Mock reserves for Sushi pair
provider
.anvil_set_storage_at(
sushi_pair.address,
U256::from(8), // getReserves slot
B256::from_slice(&hex!(
"665c6fcf00000000006407e2ec8d4f09436700000003919bf56d886af022979d"
)),
)
.await?;
// Mock WETH balance for Sushi pair
set_hash_storage_slot(
&provider,
WETH_ADDR,
U256::from(3),
sushi_pair.address,
sushi_pair.reserve1,
)
.await?;
// Mock DAI balance for Sushi pair
set_hash_storage_slot(
&provider,
DAI_ADDR,
U256::from(2),
sushi_pair.address,
sushi_pair.reserve0,
)
.await?;
let balance_of = iweth.balanceOf(*executor.address()).call().await?;
println!("Before - WETH balance of executor {:?}", balance_of);
let weth_amount_in = get_amount_in(
uniswap_pair.reserve0,
uniswap_pair.reserve1,
false,
sushi_pair.reserve0,
sushi_pair.reserve1,
);
let dai_amount_out =
get_amount_out(uniswap_pair.reserve1, uniswap_pair.reserve0, weth_amount_in);
let weth_amount_out = get_amount_out(sushi_pair.reserve0, sushi_pair.reserve1, dai_amount_out);
let swap1 = swapCall {
amount0Out: dai_amount_out,
amount1Out: U256::ZERO,
to: sushi_pair.address,
data: Bytes::new(),
}
.abi_encode();
let swap2 = swapCall {
amount0Out: U256::ZERO,
amount1Out: weth_amount_out,
to: *executor.address(),
data: Bytes::new(),
}
.abi_encode();
let arb_calldata = FlashBotsMultiCall::uniswapWethCall {
_wethAmountToFirstMarket: weth_amount_in,
_ethAmountToCoinbase: U256::ZERO,
_targets: vec![uniswap_pair.address, sushi_pair.address],
_payloads: vec![Bytes::from(swap1), Bytes::from(swap2)],
}
.abi_encode();
let arb_tx =
TransactionRequest::default().with_to(*executor.address()).with_input(arb_calldata);
let pending = provider.send_transaction(arb_tx).await?;
pending.get_receipt().await?;
let balance_of = iweth.balanceOf(*executor.address()).call().await?;
println!("After - WETH balance of executor {:?}", balance_of);
Ok(())
}It uses a FlashBotsMultiCall contract from the Flashbots simple-arbitrage repo to atomically execute a swap between Uniswap and Sushiswap WETH/DAI pools.
You can execute this simulation by running the following command on the examples repo:
RPC_URL=https://your-ethereum-endpoint \
cargo run --locked -p examples-advanced --example uniswap_u256_alloy_simulation
It should produce:
Before - WETH balance of executor 5000000000000000000
After - WETH balance of executor 5006142751241793559
We've managed to simulate exactly the same profit of ~0.00614 ETH that we've calculated before.
Summary
Rewriting your ethers-rs project could be a significant time investment. But Alloy is here to stay. Starting a migration from the calculations layer will let you reap performance benefits with minimal development effort.